목차
- 데이터마이닝의 정의와 기법 종류
- 데이터분할 (훈련용, 검증용, 테스트)
- 모형평가 (홀드아웃, 교차검증, 붓스트랩)
- 클래스 불균형 데이터
데이터 마이닝 (Data Mining)이란?
- 대용량 데이터(거래,고객,상품 데이터 등)에서 감춰진 지식, 새로운 규칙 등을 발견하고 의사 결정에 활용하는 방법
- e.g. 환자 데이터를 이용해 해당 환자에게 발생 가능성이 높은 병을 예측할 수 있음
- 데이터 마이닝 5단계:
- 1. 목적 정의
- 2. 데이터 준비 - 데이터 정제 (cleansing)로 품질 확보, 필요시 보강하여 양 확보
- 3. 데이터 가공 - 목적 변수 정의, 마이닝 소프트웨어에 적용 할 수 있게 가공 및 준비, CPU와 메모리 등 개발환경 구축
- 4. 데이터 마이닝 기법 적용 - 모델을 목적에 맞게 선택
- 5. 검증 - 결과 검증, 최적의 모델 선정
*데이터 준비와 가공 단계 구분할 줄 알아야함
데이터 마이닝 기법 5가지
- 분류 (Classification) - 기존의 분류, 정의된 집합에 배정하는 것. 선분류된 집합.
- e.g. 이 생물의 종, 속, 과는?
- 추정 (Estimation) - 연속된 변수의 값을 추정, 입력된 데이터를 통해 알려지지 않은 결과 값 추정
- e.g. 우리 가족 총 수입은?
- 연관분석 (Association Analysis) - 아이템의 연관성 파악. 카탈로그 배열, 교차판매, 공격적 판촉행사 등 마케팅 계획
- e.g. 콜라와 같이 제일 잘 팔리는 물건은?
- 군집 (Clustering) - 미리 정의된 기준으로가 아닌 레코드 자체가 가진 다른 레코드와의 유사성으로 그룹화되고, 이질성에 의해 세분화 됨
- 데이터 마이닝, 모델링 준비 단계
- e.g. 고객 특성에 따라 고객의 그룹을 형성하기
- 기술 (Description) - 데이터가 가진 특징 & 의미를 단순히 설명하는 것
*연관분석, 군집 둘다 비지도 학습
*분류는 지도 학습
*군집은 선분류 기준에 의존 x, 분류는 선분류된 집합에 의해 완성
모형평가
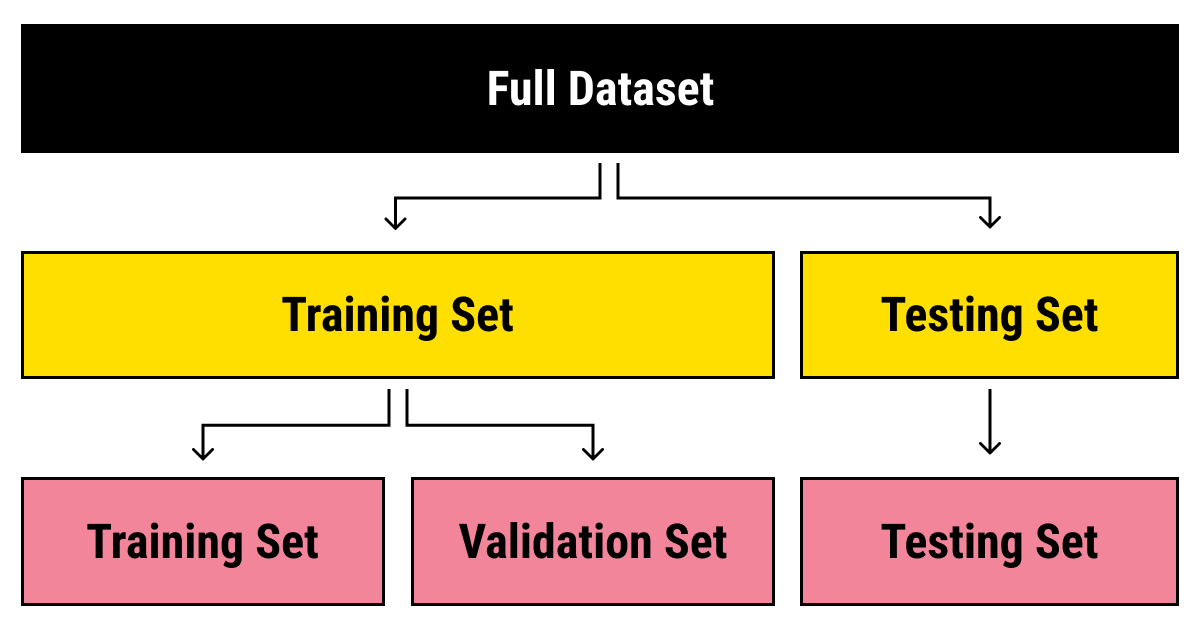
마이닝을 위한 데이터 분할
- 1) 훈련용 (training data) - 마이닝 모델 만들 때 활용 (학습용)
- 2) 검정용 (validation data) - 학습 중 모형의 과대추정/과소추정을 미세 조정하는데 활용 (overfitting 여부 확인, early stopping을 위해 사용)
- 과대적합 발생이 감지되면 빠르게 학습을 멈추기 위해 사용됨
- 3) 시험용 (test data) - 학습 종료 후 모델의 성능 검증
모형평가방법
- 홀드아웃 방법 (hold-out) - 데이터가 편향되지 않도록 2개로 분리 (train & test data)하여 과대적합 발생 여부와 성능을 평가하는 방법
- 과대적합 (overfitting): train 점수 >> test 점수
- 과소적합(underfitting): train 점수 test 점수 모두 낮은 경우
- 홀드아웃 방법은 잘못된 가설을 가정하게 되는 제2종 오류를 방지함
- 분류모형에서 불균형 데이터의 경우, 불균형 범주의 비율을 유지하도록 분할하기도함 (층화추출법)
- 사용 데이터가 많을 때 적합
- 교차확인 방법 (cross-validation) - 홀드아웃보다 많은 조각으로 나누어 여러번 검증
- 불균형 데이터에 부적합
- K-fold 교차검증: 주어진 데이터를 k개로 구분 -> k-1개의 집단을 학습용으로, 나머지는 검증용으로 사용 -> k번 반복 측정의 평균 값이 최종 값.
- LOOCV (leave one out cross validation): 1개의 관측값이 validation set로 사용, 나머지 n-1개는 train set으로 사용하여 n번 학습
- k=n인 경우의 교차 검증
- 학습 후 계산된 n개의 MSE(Mean Squared Error)를 평균하여 최종 MSE 계산
- 굉장히 많은 반복 학습으로 오래 걸림
- 데이터가 한정적이고, 새로운 데이터에 대한 에러 예측을 위한 방법

- 붓스트랩 (Bootstrap): 복원추출법 (관측치를 1번 이상 훈련용 자료로 사용함)
- 평가를 반복하는 건 교차검증과 비슷하지만, 훈령용 자료를 반복 재선정한다는 것이 차이점
- 전체 데이터 양이 적을 경우 가장 적합
- 0.632 붓스트랩 = 훈련데이터를 63.2% 사용하는 것

클래스 불균형 데이터 (Class imbalance problem)
- 일부 범주형의 관측치가 현저히 부족하여 범주 차이가 많이 나는 경우 (모형이 학습하기 힘든 상태)
- 해결방안:
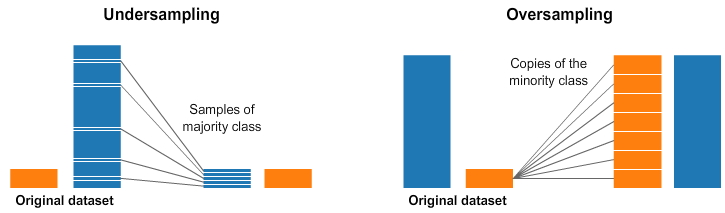
- 언더샘플링(Unsampling) - 데이터 개수를 적은 class의 수에 맞추기 (샘플링)
- 오버샘플링(Oversampling) - 데이터 개수를 많은 class의 수에 맞추기 (가상의 데이터)
- 오버샘플링 시 과적합, 노이즈 증가, 데이터 분포 왜곡, 계산 비용 증가 등 문제 발생할 수 있음
- 모델의 과적합을 방지하기 위해 교차검증 및 하이퍼파라미퍼 튜닝(조정)을 신중히 수행해야 함
'데이터분석자격증 ADsP > Part 3 데이터 분석 R' 카테고리의 다른 글
| [ADsP] 데이터마이닝 - 분류분석 (인공신경망 모형 ANN) (24) | 2024.02.21 |
|---|---|
| [ADsP] 통계분석 - 상관분석 (Correlation Analysis)을 통한 다변량 분석 (20) | 2024.02.20 |
| [ADsP] 데이터마이닝 - 분류분석 (앙상블 모형, K-NN, SVM) (14) | 2024.02.19 |
| [ADsP] 데이터마이닝 - 연관분석 (Association Analysis) 장바구니 분석 (13) | 2024.02.19 |
| [ADsP] 데이터마이닝 - 분류분석 (로지스틱회귀, 의사결정나무) + R코드 실습 (13) | 2024.02.18 |



