분류기법의 종류
- 로지스틱 회귀분석 (Logistic Regression) - 선형을 이용해 분류, 로지스틱 함수 적용
- 의사결정나무 (Decision Tree) - 트리구조로 분류 또는 회귀, 해석이 쉬움
- 앙상블(Ensemble) - 여러 모델을 결합하여 강력한 모델 생성
- K-NN (K-Nearest Neighbors) - 데이터 포인트의 가장 가까운 k개 이웃 데이터 포인트들 기반
- SVM (Support Vector Machine) - 데이터를 고차원 공간으로 매핑하여 선형/빈선형 분류 수행
- 인공신경망 모형 (ANN) - 여러 계층의 뉴런으로 구성되며, 숨겨진 계층을 통해 비선형 함수를 모델링, 딥러닝에서 적용
- 베이지안분류 (Naive Bayesian) - 베이즈 이론 기반으로, 예측변수와 클래스간의 관계를 모델링
앙상블 (Ensemble) 모형이란?
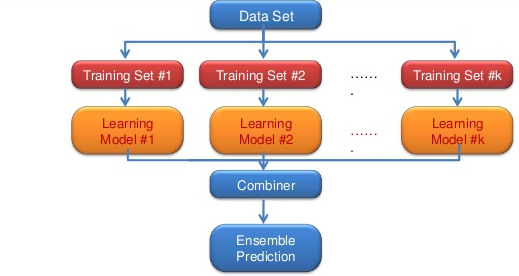
- 여러 개의 분류 모형에 의한 결과를 종합하여 분류의 정확도를 높이는 방법
- 성능 분산 -> 과적합(Overfitting) 감소 효과가 있음
- 상호 연관성이 낮은 모델을 결합할 때 가장 효과적임
- 앙상블 모형 종류: 보팅, 배깅, 부스팅, 랜덤 포레스트, 스태킹 등
- 보팅 (Voting) - 동일한 데이터를 사용하는 서로 다른 여러 개 알고리즘 분류기 사용. 각 모델의 결과를 취합하여 많은 결과 혹은 높은 확률로 나온 것이 최종 결과로 채택 (다수결)
- 스태킹(Stacking) - 기본 모델의 결과를 사용하여 메타 모델 학습을 함 (2단계 학습)
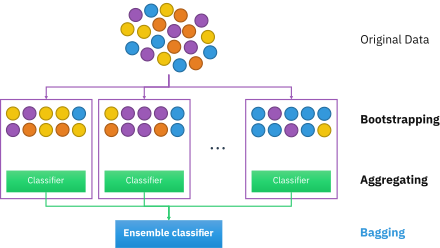
배깅 (Bagging, Bootstrap AGGregatING)
- 서로 다른 훈련데이터 샘플로 훈련하여, 서로 같은 알고리즘을 사용하는 방법
- 원 데이터에서 중복을 허용하는 크기가 같은 표본을 여러번 단순 임의 복원 추출하여 각 표본에 대해 모델을 생성하는 기법 (bootstrap 단계)
- 여러 모델이 병렬(parallel)로 학습하며, 그 결과를 집계하는 방식 (aggregate 단계)
- 같은 데이터가 여러번 추출될 수 있고, 아예 추출되지 않을 수 있음
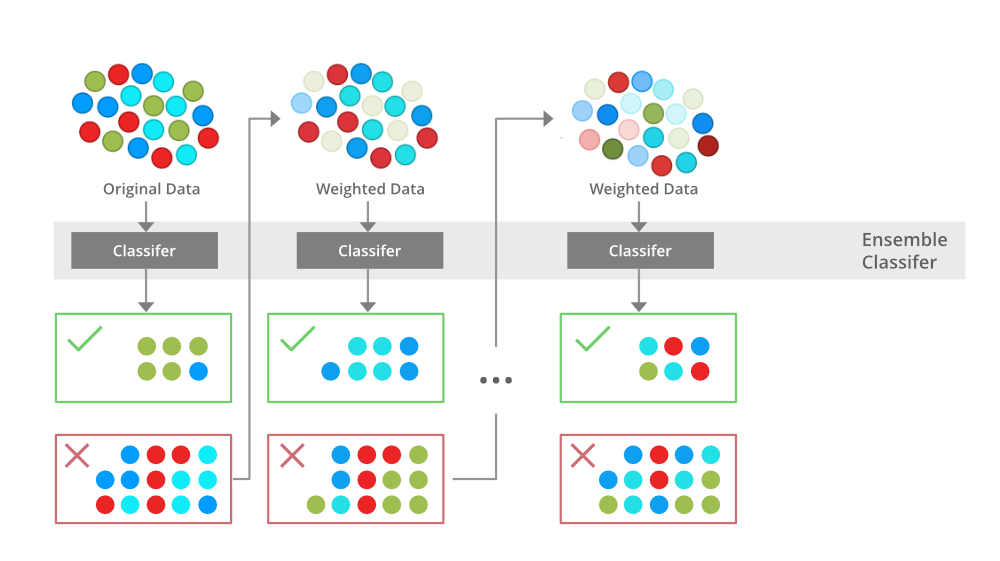
부스팅 (Boosting)
- 예측력이 약한 모형 (weak learner)들을 결합해 강한 예측모형을 만드는 방법
- 이전 모델의 결과에서 분류가 잘못된 데이터에 가중치(weight)를 부여하여 표본을 추출함
- 여러 모델이 순차적(sequential)으로 학습
- 맞추기 어려운 문제를 맞추는 것이 초점, 다른 앙상블 기법에 비해 이상치(outlier)에 민감함
- 대표적 알고리즘: AdaBoost, GradientBoost (XGBoost, Light GBM)
- *leaf-wise-node 방법은 Light GBM과 연관된 컨셉 (시험에 출제)
랜덤 포레스트 (Random Forest)
- 배깅(bagging)에 랜덤 과정을 추가한 방법
- 데이터를 자식 노드로 나누는 기준을 정할 때 모든 예측변수에서 최적의 분할을 선택하는 대신, 독립변수의 일부분만을 고려하여 성능을 높임
- 많은 의사결정 트리들이 생성됨
- 정확도와 예측력 좋음
R코드로 알아보는 랜덤포레스트
*시험에서 중요하지 않음
*랜덤 포레스트 패키지를 이용한 iris data 분석, 그래프 만들기
library(randomForest)
idx <- sample(2, nrow(iris), replace=TRUE, prob=c(0.7, 0.3))
train.data <- iris[idx==1,]
test.data <- iris[idx==2,]
randomforest <- randomForest(Species~., data=train.data, ntree=100, proximity=TRUE)
plot(randomforest)
varImpPlot(randomforest)
plot(margin(randomforest, test.data$Species))
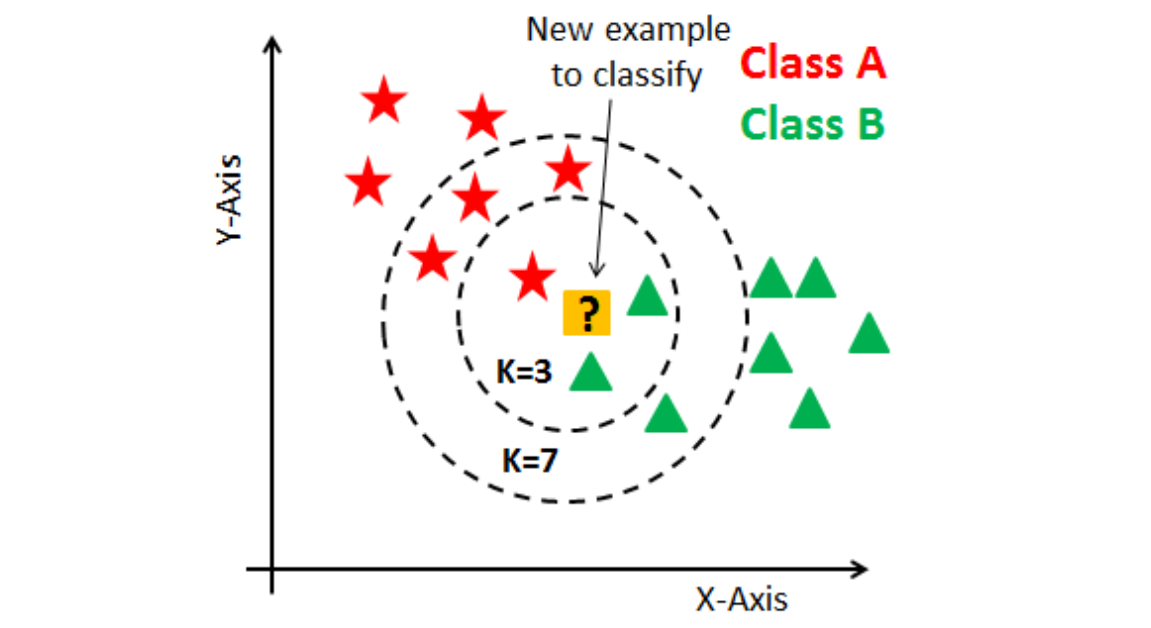
K-NN (k-Nearest Neighbors)이란?
- 새로운 데이터에 대해 주어진 이웃의 개수(k)만큼 가까운 멤버들과 비교하여 결과를 판단하는 방법
- 입력된 k값(hyper parameter)에 따라 소속되는 그룹이 달라질 수 있음
- 거리를 측정해 이웃을 뽑기 때문에, 스케일링 scaling 중요함
- lazy learning 지도학습 알고리즘 사용
- 이상치가 예측에 큰 영향을 미칠 수 있음
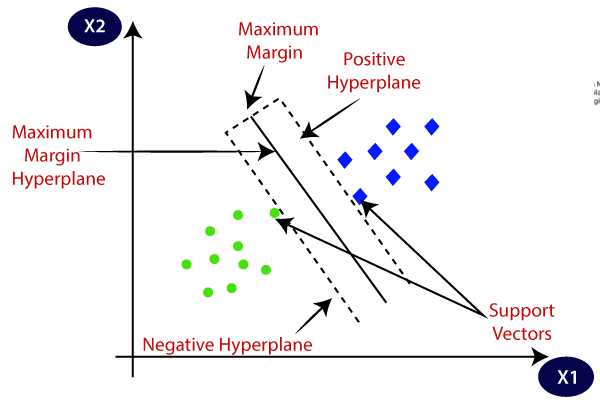
SVM(Support Vector Machine)이란?
- 성능은 좋지만, 속도는 느림
- 서로 다른 분류에 속한 데이터 간의 간격(margin)이 최대가 되는 선을 찾아 이를 기준으로 데이터를 분류하는 모델
'데이터분석자격증 ADsP > Part 3 데이터 분석 R' 카테고리의 다른 글
| [ADsP] 데이터마이닝 - 분류분석 (인공신경망 모형 ANN) (24) | 2024.02.21 |
|---|---|
| [ADsP] 통계분석 - 상관분석 (Correlation Analysis)을 통한 다변량 분석 (20) | 2024.02.20 |
| [ADsP] 데이터마이닝 - 연관분석 (Association Analysis) 장바구니 분석 (13) | 2024.02.19 |
| [ADsP] 데이터마이닝 - 분류분석 (로지스틱회귀, 의사결정나무) + R코드 실습 (13) | 2024.02.18 |
| [ADsP] 데이터마이닝 (Data Mining) 정의, 기법, 모형평가, 불균형데이터 (3) | 2024.02.18 |



