3과목 데이터마이닝 연관분석
- 연관분석 이해하기 (정의 절차 장단점)
- 연관분석의 측도 (지지도 신뢰도 향상도)
- 연관분석 알고리즘
- R코드로 보는 연관분석

연관분석(Assocation Analysis)이란?
- 연관분석: 고객들의 구매 패턴을 분석하여 의미있는 규칙을 발견하기 위한 분석
- "아메리카노를 마시는 고객이 브라우니를 먹을 확률은?"
- 장바구니분석 (장바구니에 뭐가 함께 들어있나?) 또는 서열분석 (A 다음 B는 뭘 살까)
- if-then 형태로 이루어짐: "if 아메리카노를 마시면 then 고객중 10%가 브라우니를 먹는다."
- 비지도 학습 유형
- 최소 지지도 결정 → 품목 중 최소 지지도를 넘는 품목 분류 → 2가지 품목 집합 생성 → 반복하여 빈발품목 집합 찾기
- 장점: 결과 쉽게 이해 가능, 분석 목적이 없는 경우 유용하게 활용, 간단한 자료 구조와 계산
- 단점:
- 품목수 up, 계산도 기하급수적으로 up (개선방안: 유사한 품목을 한 범주로 일반화)
- 너무 세분화된 품목으로 하면 의미 없는 분석이 될 수 있음 (개선방안: 적절히 큰 범주로 구분해 전체분석에 포함한 후, 그 결과 중에서 세부적으로 연관규칙 찾기)
연관분석의 측도
1) 지지도 (support)
- 전체 거래 중 아이템 A와 B를 동시에 포함하는 거래의 비율
- 지지도 = P(A∩B) = A∩B / 전체
2) 신뢰도 (confidence)
- 항목 A를 포함한 거래 중 A와B 동시에 포함 될 확률
- 신뢰도 = P(A∩B) / P(A) = 지지도/P(A)
3) 향상도 (lift)
- A가 구매되지 않았을 때 B의 구매확률 vs. A가 구매됐을 때 B의 구매확률 증가 비
- 향상도 = P(A∩B) /[P(A)xP(B)] = 신뢰도/P(B)
*시험에서 거래품목을 주고, 향상도를 계산하는 문제 자주 출제
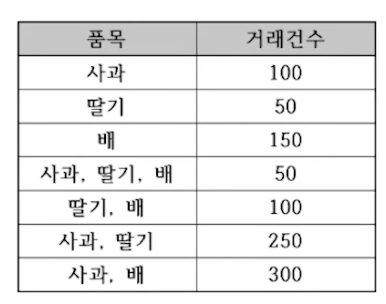
예제) 사과 --> 딸기 향상도 구하기
총합 거래 = 1000
사과 딸기 동시 거래 = 50+250=300/1000
사과 거래 = 700/1000
딸기 거래 = 450/1000
향상도 = 0.3/(0.7+0.45)=0.952
연관분석 알고리즘
- Apriori 알고리즘 - 모든 가능한 품목 부분집합의 개수를 줄이는 방법
- 최소 지지도 이상의 빈발항목집합 (frequent item set) 에 대해서만 연관규칙 계산하기
- 문제점은 아이템의 개수 up이면 계산 복잡도 up
- FP-Growth 알고리즘 - 거래내역 안에 포함된 품목의 개수를 줄여 비교하는 횟수를 줄이는 방법
- FP-TREE(Frequent Pattern Tree)을 만들어 분할정복 방식 사용
- Apriori보다 데이터베이스를 스캔하는 횟수가 작고, 분석 속도가 빠름
- 지지도가 낮은 품목부터 빈도수가 높은 아이템 집합을 생성하는 상향식 알고리즘 (순차패턴분석)
R로 보는 연관분석
dataset_"Groceries" 예제
install.packages("arules")
library(arules)
data(Groceries)
inspect(Groceries[1:3]) #거래내역 확인
rules <- apriori(Groceries, parameter = list(support=0.01, confidence=0.3))
inspect(sort(rules, by=c("lift"), decreasing=TRUE)[1:20]) #향상도 기준 내림차순으로 정렬
*함수 apriori()로 최소지지도, 신뢰도 설정 후 연관규칙분석을 할 수 있음
분석결과_
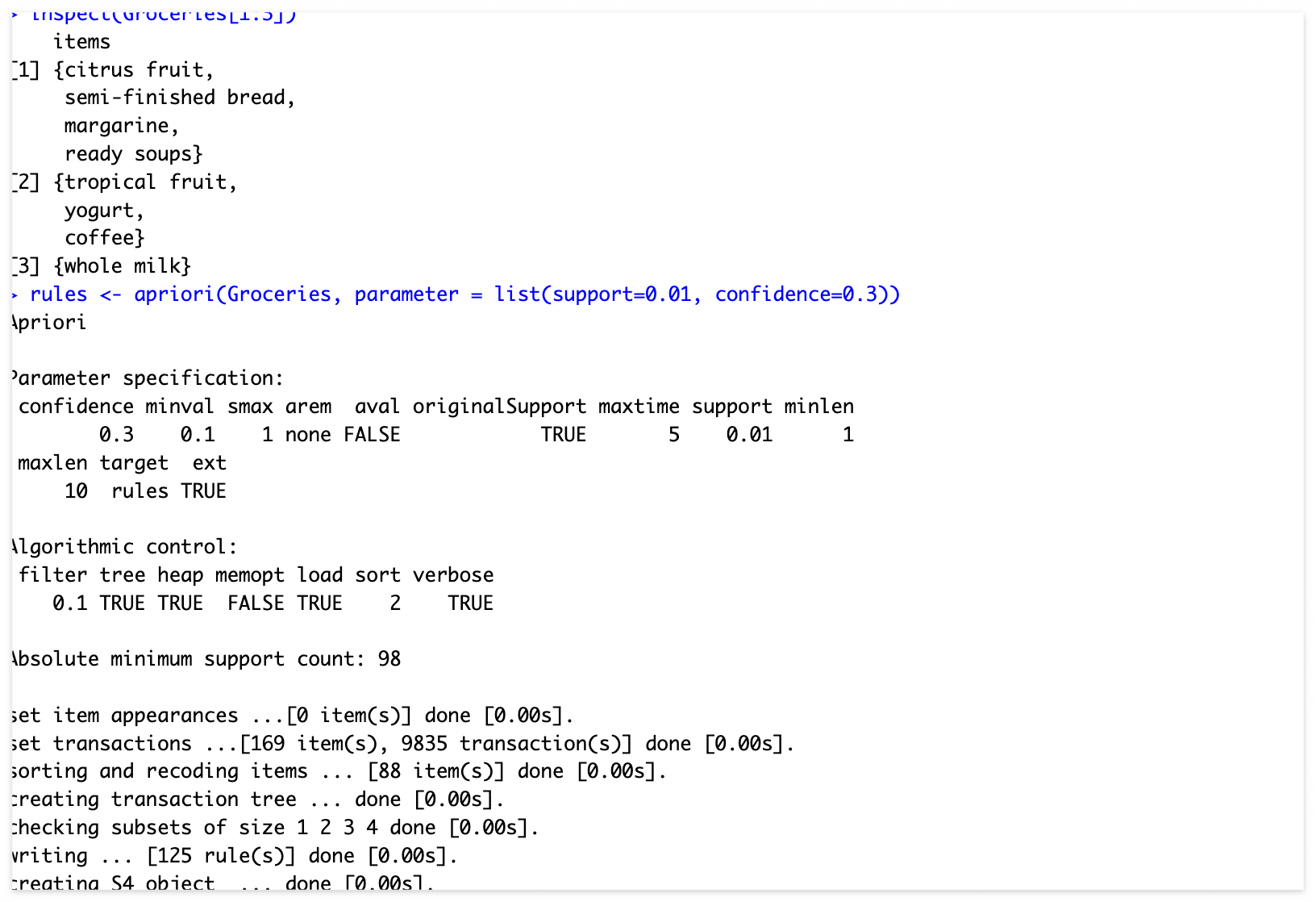
"88 items" -> 총 88개의 아이템
"set of 125 rules" -> 125개의 rule 발견
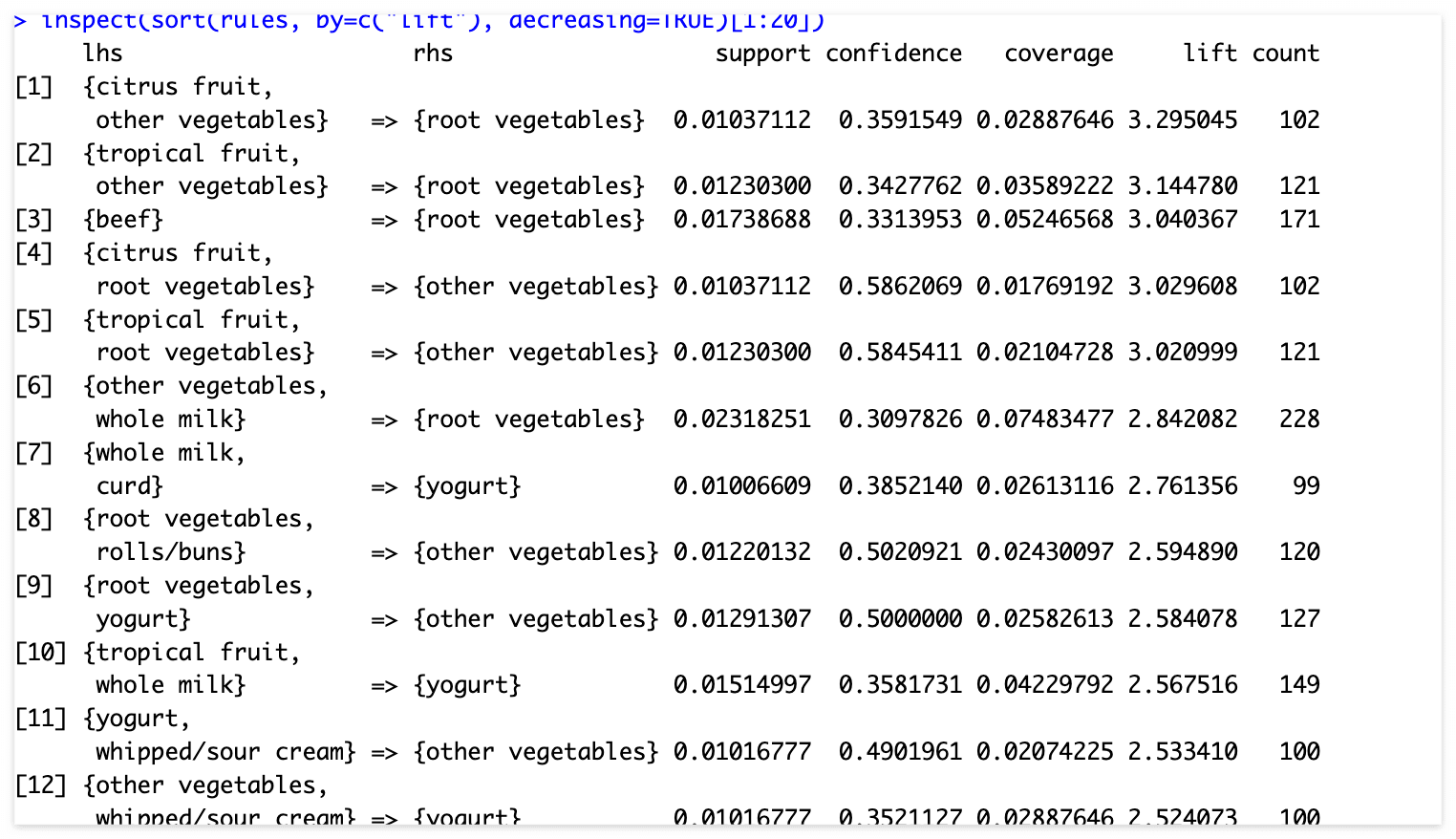
lift > 3인 경우 (상위 5건), lhs 제품을 샀을 때 rhs 제품도 구매할 확률이 약 3배 가량 높다.
*여기서 lhs란 left hand side, rhs는 right hand side
이런식으로 R로 품목들간 연관규칙을 찾을 수 있다.
'데이터분석자격증 ADsP > Part 3 데이터 분석 R' 카테고리의 다른 글
| [ADsP] 데이터마이닝 - 분류분석 (인공신경망 모형 ANN) (24) | 2024.02.21 |
|---|---|
| [ADsP] 통계분석 - 상관분석 (Correlation Analysis)을 통한 다변량 분석 (20) | 2024.02.20 |
| [ADsP] 데이터마이닝 - 분류분석 (앙상블 모형, K-NN, SVM) (14) | 2024.02.19 |
| [ADsP] 데이터마이닝 - 분류분석 (로지스틱회귀, 의사결정나무) + R코드 실습 (13) | 2024.02.18 |
| [ADsP] 데이터마이닝 (Data Mining) 정의, 기법, 모형평가, 불균형데이터 (3) | 2024.02.18 |



