분류 모형 평가지표
1) 오분류표
2) ROC 그래프
3) 이익도표
4) 카파 상관계수
오분류표
*시험에 자주 출제, 공식 무조건 외우기
*실제, 예측, true, false의 위치를 제일 먼저 확인할 것.
T/F
|
P/N
|
| => TP, TN, FP, FN 으로 구성됨 | |
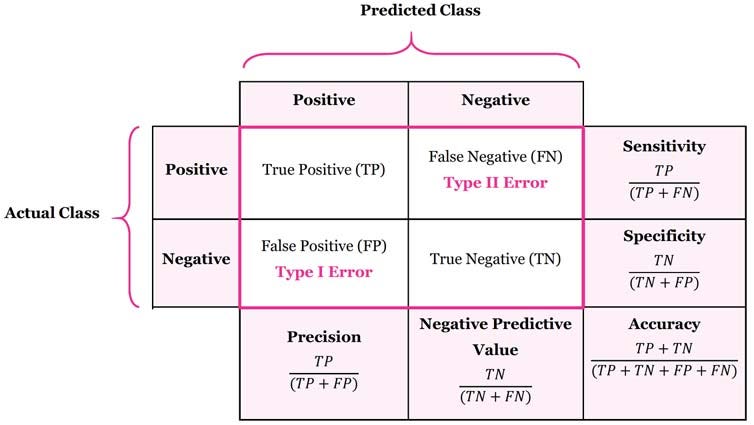
- 정밀도 (Precision) - True라고 예측한 것 중 실제로 True인 것
- 재현율 (Recall) - 실제로 True인 것 중에 예측값이 True인 것
- *Recall은 민감도(sensitivity)와 같은 것
- 정확도 (Accuracy) - 전체 예측에서 옳은 예측의 비율
- 오분류율 (Error rate) - 전체 예측에서 틀린 예측의 비율 (1-Accuracy)
- 특이도 (Specificity) - 실제로 False 인 것 중 예측도 False여서 맞춘 것의 비율
오류
- FP: 제1종오류
- FN: 제2종오류
- *쉽게 외우는 방법: P에는 1자가 하나, N에는 1자가 두개
F1-Score
- F1 score은 불균형한 데이터(imbalance data)평가에 주로 사용됨
- precision과 recall의 조화평균
- 공식: F1 = (2*P*R) / (P+R)
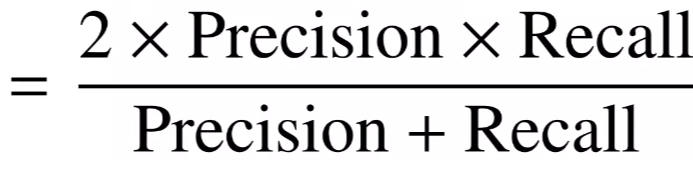
*Recall, precision 쉽게 외우는 방법: 실rec예pre
예시) 아래 오분류표의 F1 score을 구해라.
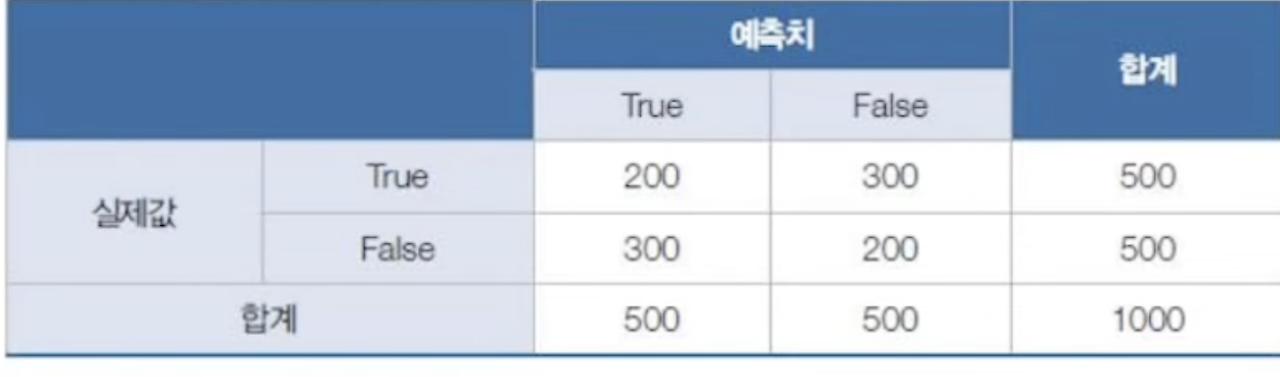
더보기
P = 200/500
R = 200/500
F1 = 2*0.4*0.4/(0.8)=0.4
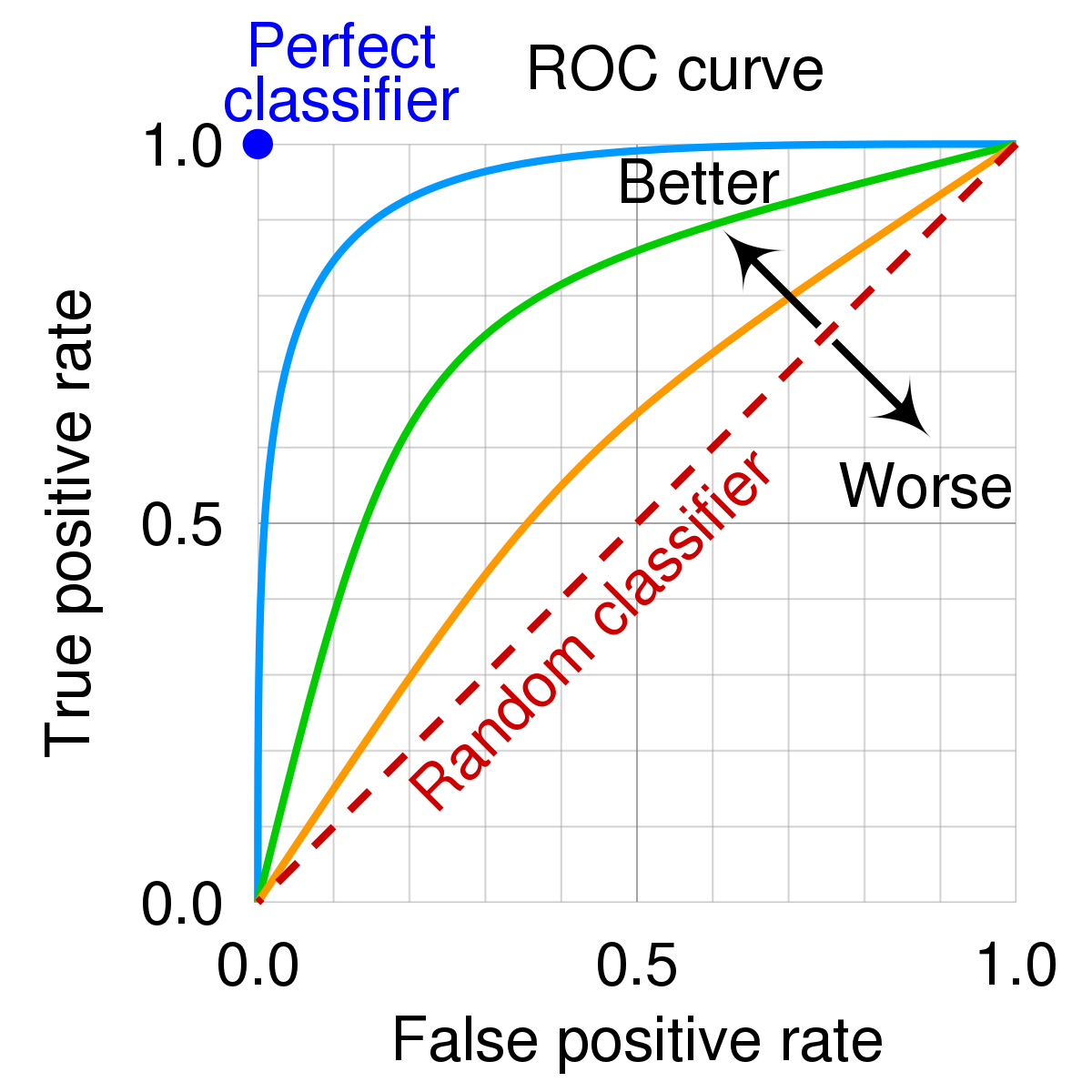
ROC Curve (Receiver Operating Characteristic)
- x축 = FP rate, y축 = 민감도 (sensitivity/recall)
- AUC(Area under the Curve) - 곡선 아래 면적이 넓을수록 좋은 것으로 평가됨
- AUC 값은 0~1 (1이 최댓값이므로 제일 좋은 것)
이익도표 (Lift Table)
- 분류모형의 성능을 평가, 주로 불균형 데이터 집합에 사용
- 예측이 얼마나 잘 이루어졌는지 나타내기 위해 임의로 나눈 각 등급별로 반응 검출율, 반응률, 향상도(lift) 등 정보를 산출
카파 상관계수 (Kappa)
- 코헨(Cohen)의 상관계수로 두 평가자의 평가가 얼마나 일치하는지 평가하는 값
- 0~1사이 값, 1에 가까울수록 일치도 높음
'데이터분석자격증 ADsP > Part 3 데이터 분석 R' 카테고리의 다른 글
| [ADsP] 지도학습 vs. 비지도학습 (머신러닝의 알고리즘) (23) | 2024.02.23 |
|---|---|
| [ADsP] 데이터마이닝 - 군집분석 (Cluster Analysis) (23) | 2024.02.23 |
| [ADsP] 데이터마이닝 - 분류분석 (인공신경망 모형 ANN) (24) | 2024.02.21 |
| [ADsP] 통계분석 - 상관분석 (Correlation Analysis)을 통한 다변량 분석 (20) | 2024.02.20 |
| [ADsP] 데이터마이닝 - 분류분석 (앙상블 모형, K-NN, SVM) (14) | 2024.02.19 |



