오늘의 AI 툴
Sora
챗지피티를 개발한 OpenAI가 최근에 영상 생성 AI 모델 Sora를 공개했습니다. Runway의 Gen2, Pika AI, 등 기존에도 여러 text-to-video 모델들이 존재 했는데요, Sora는 지금껏 공개된 모델들과는 차원이 다른 퀄리티를 선보입니다. 이 모델은 출시 되자마자 영상업계에 패러다임을 바꾼다는 평이 쏟아졌는데요, 오늘은 Sora의 경쟁력과 학습원리에 대해 알아보고자 합니다.
Sora의 놀라운 기능 & 기술력
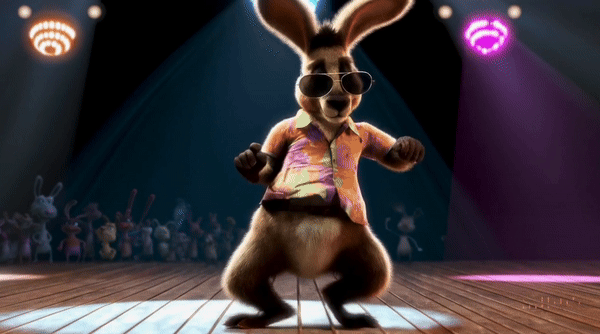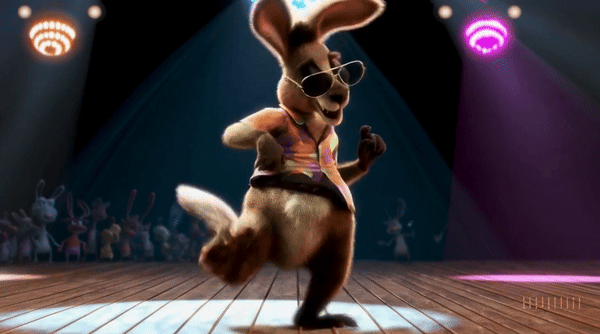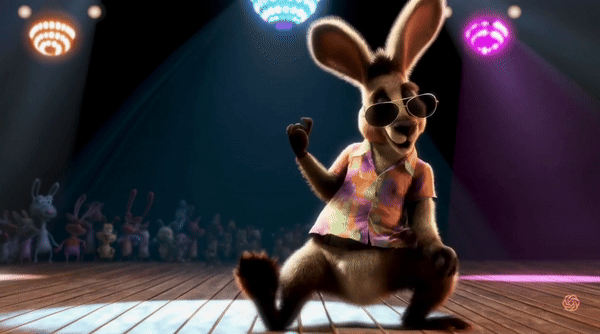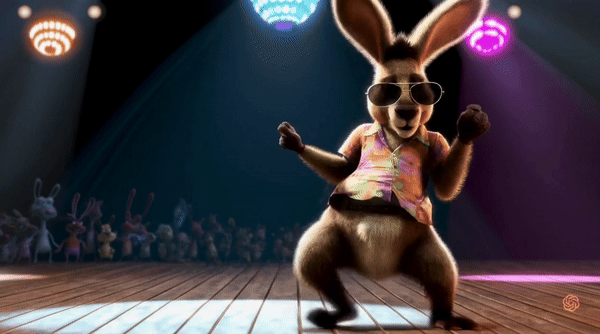
텍스트 프롬프트를 입력하면 1분짜리 고화질 영상까지 만들 수 있습니다. 지금껏 영상 AI 모델들은 최대 20초 정도의 영상을 만들 수 있었으나, Sora는 이 한계를 넘어 최대 1분 길이의 1080x1920 해상도의 영상을 제작할 수 있습니다.
여러 캐릭터, 특정 모션, 디테일한 피사체와 배경을 포함한 복잡한 장면들을 구현하는 기술이 뛰어납니다. 언어를 깊이 이해하고 있어서 요구사항을 정확하게 해석할 수 있고, 놀랍도록 정교하고 생생한 영상을 만들 수 있습니다.


이 모델은 프롬프트에 주어진 텍스트 자체를 이해하는 것을 넘어서 물체들이 실제 세계에 어떻게 행동하는지 이해합니다. 위에 영상의 캡쳐본을 보면 간단한 프롬프트만으로도 스노글로브의 빛 반사, 지하철 창문에 비친 반사 등을 정말 자연스럽게 표현한 것을 볼 수 있죠.
한 동영상 안에 다양한 샷 (영상 각도)를 만들 수 있습니다. 아래 영상은 Sora에 도쿄 거리를 걷고 있는 여성에 대한 프롬프트를 넣어 만들어낸 결과입니다. 영화의 한 장면 같은 자연스러운 카메라워크와 여러 샷 연출을 볼 수 있습니다.

video-to-video editing: 입력값으로 영상을 넣어, 배경을 바꿀 수도 있습니다. 아래를 보면, 기존 영상의 배경을 정글로 바꿔달라는 프롬프트를 통하여 영상이 어떻게 변화했는지 볼 수 있습니다.

extending generated videos: 기존 영상의 앞부분이나 뒷부분을 확장할 수 있습니다. 예를 들어, 아래 3개의 영상들은 모두 하나의 영상을 기반으로 앞부분의 장면을 추가로 영상을 늘렸습니다. 그렇기 때문에 뒷부분은 동일합니다.


다른 AI 툴들과는 다른 원리? Diffusion Transformer 모델
OpenAI 웹사이트에 친절히 설명되어있는 Technical Report를 보면 개발 과정을 볼 수 있습니다.
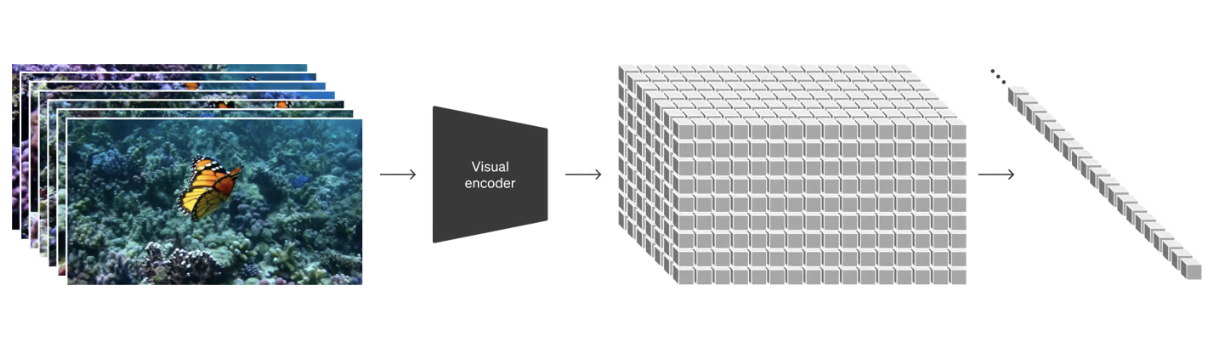
LLM(Large Language Model)에서 텍스트 토큰을 사용해 데이터 훈련을 하는 것처럼, Sora는 비주얼 패치 (visual patch)라고 하는 데이터 단위의 모음으로 표현합니다. 우선, 비디오들을 visual encoder로 프레임 단위로 쪼갭니다. 이 때 분해되는 단위가 Spacetime Patch입니다. 이렇게 시각적 데이터를 패치로 분해함으로써 다양한 해상도, 기간, 종횡비를 가진 비디오와 이미지들을 효율적으로 학습할 수 있게 됩니다. 각각 텍스트 묘사와 다시 비교하고 검증한 후, 다시 배열하여 이어붙이는 방식으로 고품질의 비디오를 생성한다고 합니다.

처음에 비디오를 압축하는 과정에서 비디오의 차원을 줄였기 때문에 학습 및 생성 속도가 빨라지며 작업의 효율이 올라갑니다. 그리고 비디오의 노이즈(중요하지 않은 정보)를 제거함으로써 새로 생성된 비디오의 품질을 향상시킬 수 있습니다.
Sora가 개선해야 하는 부분?
그러나 아직까지는 세계 시뮬레이터가 되기에는 한계가 있습니다. 복잡한 장면을 물리학적으로 정확하게 만들지 못하거나, 상황의 상호작용을 이해하는데에 어려움을 겪을 수 있다고 합니다. 예를 들어, 어떤 사람이 쿠키를 한입 베어 먹은 후에 쿠키의 모양이 그대로인 장면이 나올 수 있다는 말이죠. 또한, 왼쪽과 오른쪽을 혼합하는 등 공간적 디테일을 놓칠 수 있습니다.

OpenAI 공식 웹에서 더 다양한 샘플 영상들을 볼 수 있습니다!
Sora: Creating video from text
The current model has weaknesses. It may struggle with accurately simulating the physics of a complex scene, and may not understand specific instances of cause and effect. For example, a person might take a bite out of a cookie, but afterward, the cookie m
openai.com
'AI Tools > 예술 (Art & Music)' 카테고리의 다른 글
| 나도 작곡가가 될 수 있다? 나만의 음악 제작 Suno AI 사용법 (무료) (20) | 2024.02.10 |
|---|---|
| 텍스트를 애니메이션으로! Pika AI 툴 소개 (Discord 서버, 사진을 영상으로 바꾸기) (16) | 2024.02.08 |
| Canva로 무료 AI 이미지/그림/동영상 생성하는 방법 (초간단!) (56) | 2024.01.30 |


