*ADsP 37회 시험 기출문제 기반 풀이와 내용정리입니다. "답"을 열어 답과 풀이를 확인하고, 아래에 키워드와 개념을 학습하세요.
*전부 객관식 문제입니다.
3과목 <데이터의분석>
Q. sleep dataset의 변수는 수면제 종류 1과 2이다. 1과 2 수면제의 수면시간 증가량 평균이 통계적으로 유의미한 차이가 있는지를 검정한 결과에 대한 해석으로 적절하지 않은 것은? (R코드해석)
Two Sample t-test
t = -1.8608, df = 18, p-value = 0.07919
alternative hypothesis: true difference in means between group 1 and 2 is not equal to 0
95% confidence interval:
-3.363874 0203874
sample estimates:
mean in group 1: 0.75
mean in group 2: 2.33수면제 2가 수면제 1보다 효과가 있다.
*p-val (0.79)가 0.05보다 크기 때문에 귀무가설 채택 => 평균차이가 없다 => 수면제 2가 효과가 더 크다고 볼 수 없음
*R코드해석
독립변수 - group 1,2 (명목척도)
종속변수 - 수면시간증가량 (비율척도)
df = 18 = n-2, 표본수 = n = 20 (관측치)
two sample t-test 독립변수 2개
df (자유도) = n-2
귀무가설과 대립가설 정의하기:
- 귀무: 평균차이가 없다
- 대립: 평균차이가 있다
일반적으로 유의수준은 0.05
p-value 가 0.05보다 클 경우 => 귀무가설 채택
척도 종류:

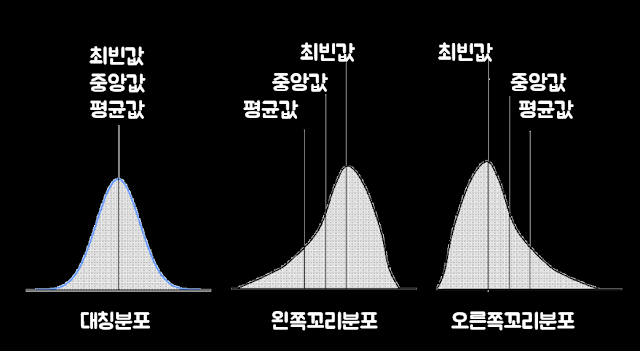
Q. Hitters dataset의 Salary변수의 summary() 함수 결과에 대한 해석 중 옳지 않은 것.
summary(Hitters$Salary)
Min 1st Qu Median Mean 3rd Qu. Max. NA's
67.5 190.0 425.0 535.9 750.0 2460.0 59왼쪽 꼬리분표 모양이다.
*오른쪽으로 skewed 되어있음 => 오른쪽 꼬리분표이다
최빈값 - 중앙값 - 평균값 순서
수치형 데이터 R 코드를 보고 알아야할 것:
- 꼬리분표 모양은 무엇인지 (왼쪽, 정규, 오른쪽)
- 중앙값은 무엇인지
- 평균값은 무엇인지
- 척도 종류? (명목, 등간, 비율, 서열)
- 결측값 유무
Q. chickwts dataset에 대한 상자그림(box plot) 결과이다. 이를 통해 추론 가능한 사실로 옳지 않은 것.

chickwts dataset은 이상치가 없다.
*Sunflower에 이상치 3점 존재.
*feed type는 범주형
casein 중위수가 가장 큼
R코드와 box plot을 통해 알 수 있는 것
- 이상치 유무?
- 최대값?
- 중앙값(중위수)?
- 변수 종류: 범주형? 수치형?
Q. 불순도 측정 결과이다. 지니 지수의 계산결과로 옳은 것은?
(다이어그램) 마름모, 원, 원, 원, 원
0.32
*k = 5
마름모 = 1개 -> (1/5)^2
원 = 4개 -> (4/5)^2
Gini = 1-[(1/5)^2+(4/5)^2] = 1-(0.04+0.64) = 1-0.68 = 0.32
지니 지수 구하는 방법: 공식

k = 범주 갯수 (class)
지니 지수가 작을수록 치우친 정도가 큼 => 분류가 잘된다
Q. 고차원의 데이터를 이해하기 쉬운 저차원의 뉴런으로 형상화 학습 기법은?
자기조직화지도 (SOM)
*다차원 척도법은 유사성과 미유사성을 고려해 차원을 축소하는 것, 그러나 뉴런의 사용 x
*SOM =
고차원 -> 저차원 하는 방법:
- 변수선택
- 차원축소기법
자기조직화지도(Self Organizing Map): 비지도 신경망, 고차원 데이터 -> 저차원 뉴런으로 정렬
- 입력층과 경쟁층
Q. 스피어만 상관계수에 대한 설명으로 옳지 않은 것?
두 변수 간의 비선형적인 관계는 나타낼 수 없다.
*스피어만은 비선형도 나타낼 수 있음. 피어슨은 불가능.
Q. 다음 중 확률 및 확률분포에 대한 설명으로 옳지 않은 것.
확률변수 x가 구간의 모임인 숫자값을 갖는 확률분포함수를 이산형 확률 밀도함수라 한다.
*이산형 확률 질량함수이라 한다.
*밀도함수는 연속형 변수에 대한 확률 분포
모든사건의 확률은 0~1 사이.
배반 사건들(서로 동시에 일어날 수 없는 사건)의 교집합은 공집합.
두 사건이 독립이라면, 영향을 주지 않기 때문에 조건부 확률과 다름.
Q. 아래 거래 데이터에서 연관규칙 사과 -> 딸기의 향상도로 옳은것.
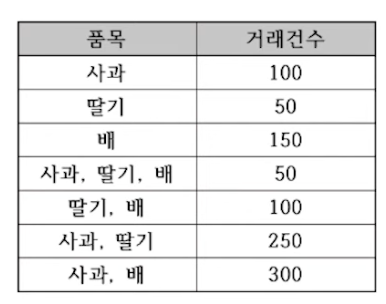
95.2%
*총합 = 1000
사과 딸기 동시 거래 = 50+250=300/1000
사과 거래 = 700/1000
딸기 거래 = 450/1000
0.3/(0.7+0.45)=0.952
향상도 lift = P(A∩B)/[P(A)xP(B)]
Q. 모집단의 크기가 비교적 작을 때 주로 사용하며 표본의 재추출이 가능한 표본 추출방법은?
복원추출법
Q. 그래프에서 TV광고수에 따른 Sales 값을 scatter plot으로 나타냈다. 알맞지 않은 것은? (회귀모델)
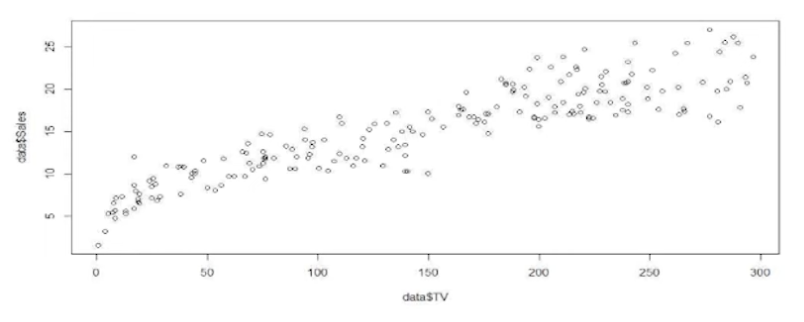
TV광고가 많아질수록 Sales의 분산은 동일하다.
*분산은 줄어든다
독립(설명변수) - tv광고수
종속 - 판매량
Q. 분석기법 유형이 나머지와 다른 것?
주성분 분석 (PCA)
*PCA는 차원 축소 기법
*나머지는 관계를 나타내는 분석
다중회귀분석
상관관계분석
교차분석
Q. 확실하게 증명하고 싶은 가설로, 뚜렷한 증거가 있어야 채택할 수 있는 가설은?
대립가설
*우리가 증명하고자 하는 가설을 대립가설이라 함 (alternative hypothesis)
Q. 신경망 노드 중 무작위로 노드를 선정하여 다수의 모형을 구성하고 학습한 뒤 각 모형의 결과를 결합해 분류 및 예측하는 기법은?
드롭아웃
Q. "고차원의 데이터를 선형 연관성이 없는 저차원의 데이터로 차원을 축소, 데이터 탐색의 시간과 노력을 효율적으로 사용할 수 있게 해주는" 기법은?
주성분 분석
Q. 다음 중 통계적 추론에 대한 설명으로 옳지 않은 것?
신뢰수준 95%의 의미는 추정값이 신뢰구간 내에 존재할 확률이 95%라는 것이다.
*신뢰구간 중 약 95%가 실제 모수를 포함한다는 의미
*점추정(point estimation) - 표본을 이용하여 모집단의 특성을 단일한 값으로 추정하는 방법
Q. 모델평가에 대한 설명으로 옳지 않은 것?
검증데이터는 모델의 성능을 검증할 때 사용한다.
*테스트데이터가 성능 검증할때 사용
모델 평가를 위한 데이터 3가지: 학습, 검증, 데스트
1. 학습데이터 - 모델을 학습할 때 가중치(weight)를 찾기 위한 데이터. 모델을 적합하게 만들기 위해 사용.
2. 검증데이터 - 학습과정 중 모델을 미세 조정, 정확도를 평가하여 과대적합과 과소적합을 줄이기 위한 데이터
3. 테스트데이터 - 모델의 정확도를 평가하기 위한 데이터. 전체 데이터의 대표성을 가져야함.
Q. 다음 중 분류모형의 평가를 위해 사용하는 지표로 가장 거리가 먼 것?
덴드로그램 (dendrogram)
*덴드로그램은 군집화 모델
분류모델 평가지표:
- 혼동행렬 (정확도, F1 score)
- ROC curve를 사용한 AUC
- 향상도 곡선
Q. 백색잡음에 대한 설명으로 옳은 것?
특정 시계열 데이터의 모든 백색잡음에 대한 합은 0.
"백색잡음"하면 -> 시계열
Q. 측정 대상의 속성을 측정하여 정량화하는 척도에 대한 설명으로 옪지 않은 것은?
등간척도: 모든 사칙연산이 가능하고 혈액형, 학력 등이 이에 해당된다.
*범주이기 때문에 명목형에 해당됨
명목
서열
등간
비율
Q. 군집분석에 대한 설명으로 적절하지 않은 것?
군집 간의 이질성과 군집 내의 동질성이 모두 낮을 수록 효과적이다.
*군집간의 이질성, 군집 내의 동질성을 최대화하는 것이 효과적
"군집분석"하면 -> 유사성
Q. 연관규칙에 대한 설명으로 옳지 않은 것?
품목수가 증가해도 분석에 필요한 연산수는 증가하지 않는다.
*연산 복잡도 증가
Q. 아래 회귀모델에 대한 설명 중 옳지 않은 것은?
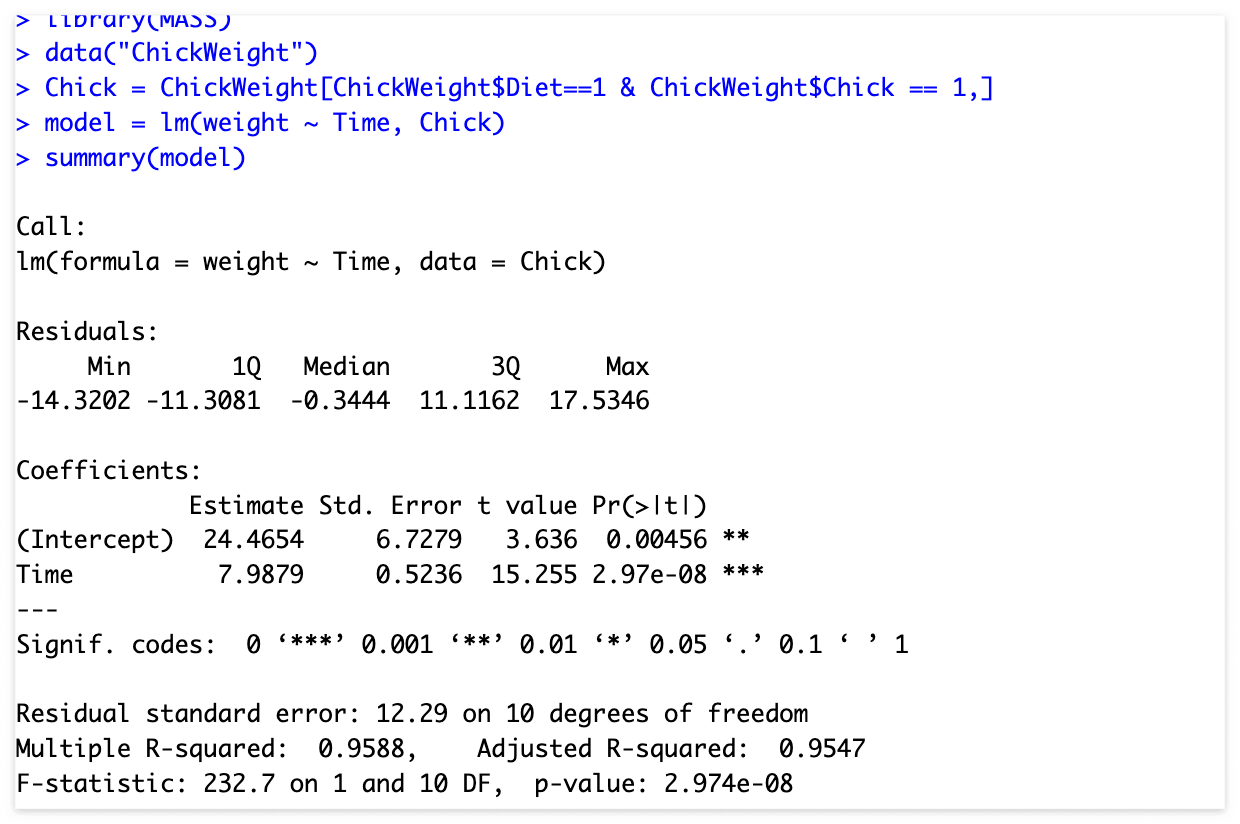
time이 1 증가할 때, weight가 5.99 증가한다.
*7.9879만큼 증가함.
F-통계량 = 232.7 => 유의함
R 경정계수 = 0.95, (1에 가까움) => 유의함
weight = B1 + B0*time = 24.4 + 7.98*time
p-value < 0.05, 대립가설 채택 => 유의미함
Q. 거래 데이터에서 연관규칙 A -> B의 신뢰도는?
| 거래번호 | 항목 |
| 1 | A |
| 2 | A,B |
| 3 | A,B,C |
| 4 | A,C |
50%
*P(A) = 4/4
P(AnB) = 2/4
신뢰도 = (1/2)/1
Q. 다중공선성(multicollinearity)에 대한 설명으로 옳지 않은 것은?
다중공선성이 발생하는 독립변수들은 표본의 크기가 관계없이 발생함.
*관계있음
분산팽창요인(VIF)>10, 다중공선성 문제 있음
해결방법: 변수 제거
표본수가 증가해도 VIF에서 결정계수는 크게 변하지 않음.

'데이터분석자격증 ADsP > 기출문제' 카테고리의 다른 글
| [ADsP] 39회 기출 3과목 문제풀이 + 개념정리 (0) | 2024.02.23 |
|---|---|
| [ADsP] 38회 기출 단답형 문제 풀이 + 개념정리 (1,2,3과목) (0) | 2024.02.20 |
| [ADsP] 38회 기출 2과목 <데이터분석기획> 문제 풀이 & 개념 정리 (객관식) (3) | 2024.02.17 |
| [ADsP] 38회 기출 1과목 <데이터의이해> 문제 풀이 & 개념 정리 (객관식) (1) | 2024.02.16 |
| [ADsP] 37회 기출 단답형 문제 풀이 + 개념정리 (1,2,3과목) (19) | 2024.02.15 |



